RNNを用いた言語モデル (RNN LM)
Interspeech 2010でBrno UniversityのToma´s Mikolov氏らによって発表された論文。RNN LMは、ESPnetにも実装されている。
出典:Recurrent Neural Network Based Language Model
概要
RNN (Recurrent Neural Network) を言語モデルに使う試みは、Bengioらによって提案されている。しかし、提案されているFeed Forward Networkは、事前に訓練されている必要のあるContextの長さが固定でないといけない制約があった。したがって、先行する5-10語の単語のみを用いて学習することになるため、長い文章で性能が上げられない問題があった。このため、長さに制約のないRNNを用いることにした。また、Goodman[2]によると、単一のモデルより、複数のモデルを組みあせた方が性能が良いことがわかっており、mixture modelingも行っている。
モデルの概要
入力x(t)はt番目の単語w(t)とt-1番目までの隠れ層を結合したものを利用する。出力yに次に出現しそうな単語の確率を返す。f(z)は活性化関数としてシグモイド関数を用い、g(z)はSoftmax関数を用いる。訓練時にはバックプロパゲーションとしてSGDを利用。

エラーベクトルとして、期待される単語の1-Nエンコーディングと予測された値との差分を訓練の各ステップで計算される。
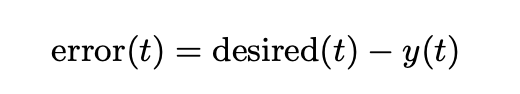
RNNのモデルには、SimpleRNNやElman Networkを用いた。統計的言語モデルの性質として、訓練用データにあまり出現しない人名が、テスト用データで繰り返し出現した場合、この人名は低い確率となってしまう。この問題に対応するため、テストデータでも訓練を行っている。これをDynamicモデルと呼ぶ。
Dynamicモデルの仕組みは、Backoff model における caching techniqueに似ているが、異なる点として、ニューラルネットワークを使っているので、“Dog” と ”Cat”に関連がある状態で、”Dog”の頻度が高い場合、”Cat”の確率も同様に上がる特徴がある。
Feed Forward Networkが層のサイズ、隠れ層の数、単語の長さなど複数のパラメータのチューニングが必要なのに対し、RNNは隠れ層の数のみで良い。また、パフォーマンス向上のために、まれにしか出現しない単語は、出力を計算せず一定値にしている。
評価
WSJデータセットとNIST05データセット。全てのケースでRNNLM (3つのDynaminc RMM LMを利用) を使ったモデルがベースラインより低いWERを達成できた。
Leave a comment